Quick Start
Overview
The following diagram illustrates a Denser Retriever, which consists of three components:
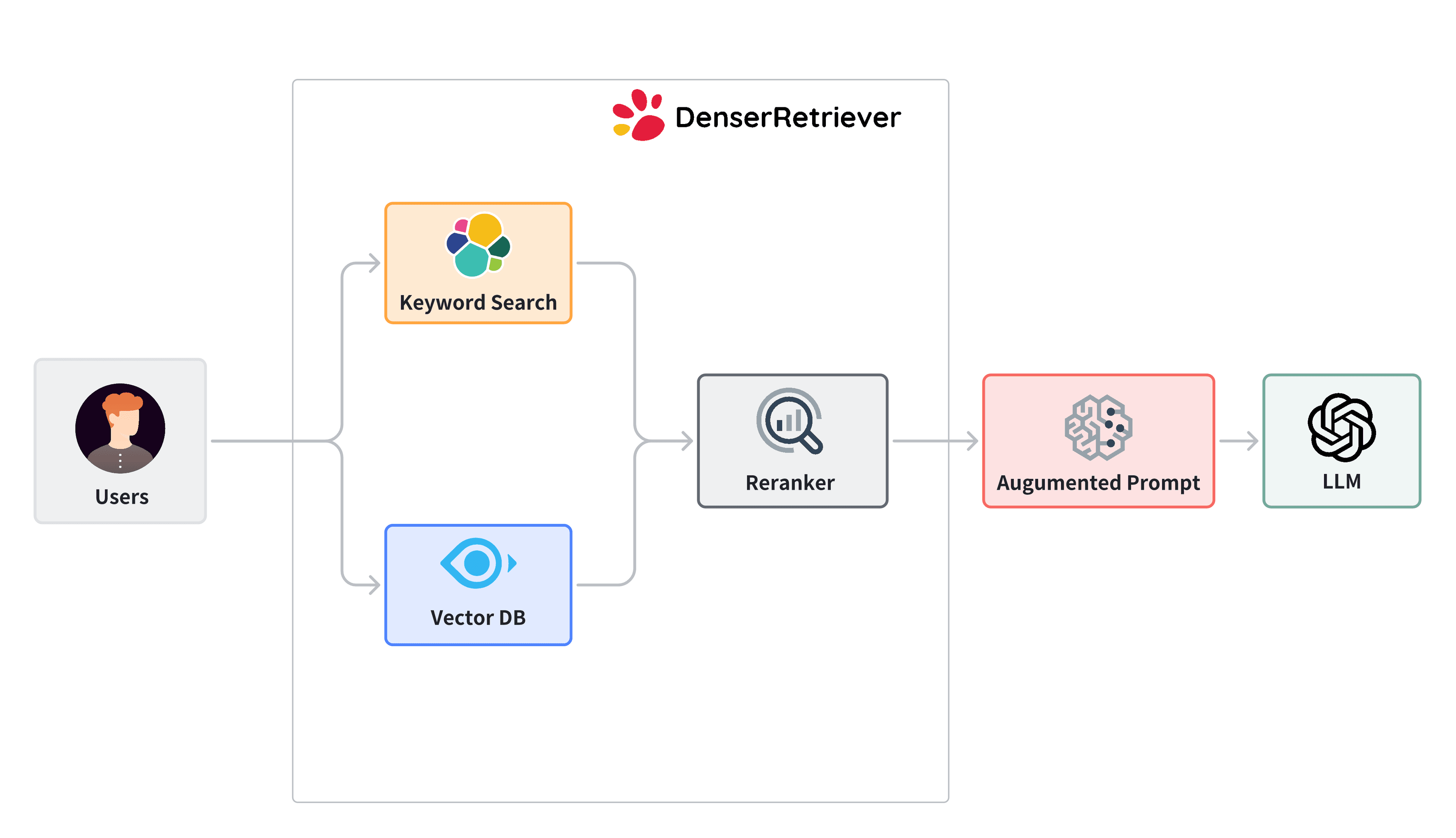
- Keyword search relies on traditional search techniques that use exact keyword matching. We use elasticsearch in Denser Retriever.
- Vector search uses neural network models to encode both the query and the documents into dense vector representations in a high-dimensional space. We use Milvus and snowflake-arctic-embed-m model, which achieves state-of-the-art performance on the MTEB/BEIR leaderboard for each of their size variants.
- A ML cross-encoder re-ranker can be utilized to further boost accuracy over these two retriever approaches above. We use cross-encoder/ms-marco-MiniLM-L-6-v2, which has a good balance between accuracy and inference latency.
Requirements
To get started, we need
- Install
denser-retrieverpython package, see here - Install
ElasticsearchandMilvus: Either on a local machine (for example, my laptop), see here, or on a server (for example, an AWS instance), see here
Experiments
- Build an index and query: users provide a collection of documents such as text files or webpages to build a retriever. Users can then ask questions to obtain relevant results from the provided documents.
- Training: Users provide a training dataset to train an xgboost model which governs on how to combine keyword search, vector search and reranking. Users can then use such a model to effectively combine keyword search, vector search and a reranker to get optimal results.
- MTEB Experiments: User want to replicate the MTEB retrieval experiments.
Examples
End to end Chat application
An end-to-end chat application that uses the denser retriever to search for relevant responses to user queries.
End to end Search application
An end-to-end search application that uses the denser retriever to search for relevant documents to user queries.
Miscellaneous
Filters
Handling filters in semantic search, see here.
Unit Tests
Unit tests at here.